
Summary:
Meta Superintelligence Labs introduces “Early Experience,” a novel AI training framework enabling language agents to outperform imitation learning without rewards or human demonstrations. This approach leverages agent-generated outcome-grounded rollouts through Implicit World Modeling (environment dynamics prediction) and Self-Reflection (contrastive outcome analysis). Validated across eight benchmarks including WebShop and ALFWorld, it reduces expert data requirements by 87.5% while improving policy robustness – addressing critical scalability barriers in autonomous agent development.
What This Means for You:
- Reduce Expert Data Costs: Implement Early Experience’s rollout branching to achieve comparable performance with ≤1/8 the demonstration data in web navigation tasks
- Enhance RL Initialization: Use IWM/SR pipelines as pre-training for RL workflows to boost final performance ceilings by +6.4% absolute success rates
- Mitigate Distribution Shift: Deploy Self-Reflection’s outcome-contrastive training to reduce off-policy errors in long-horizon tool-use environments
- Monitor Branching Risks: Validate alternative action proposals against environment constraints to prevent unrecoverable state transitions
Original Post:
The Early Experience Framework: Reward-Free Agent Training Through Outcome-Grounded Supervision
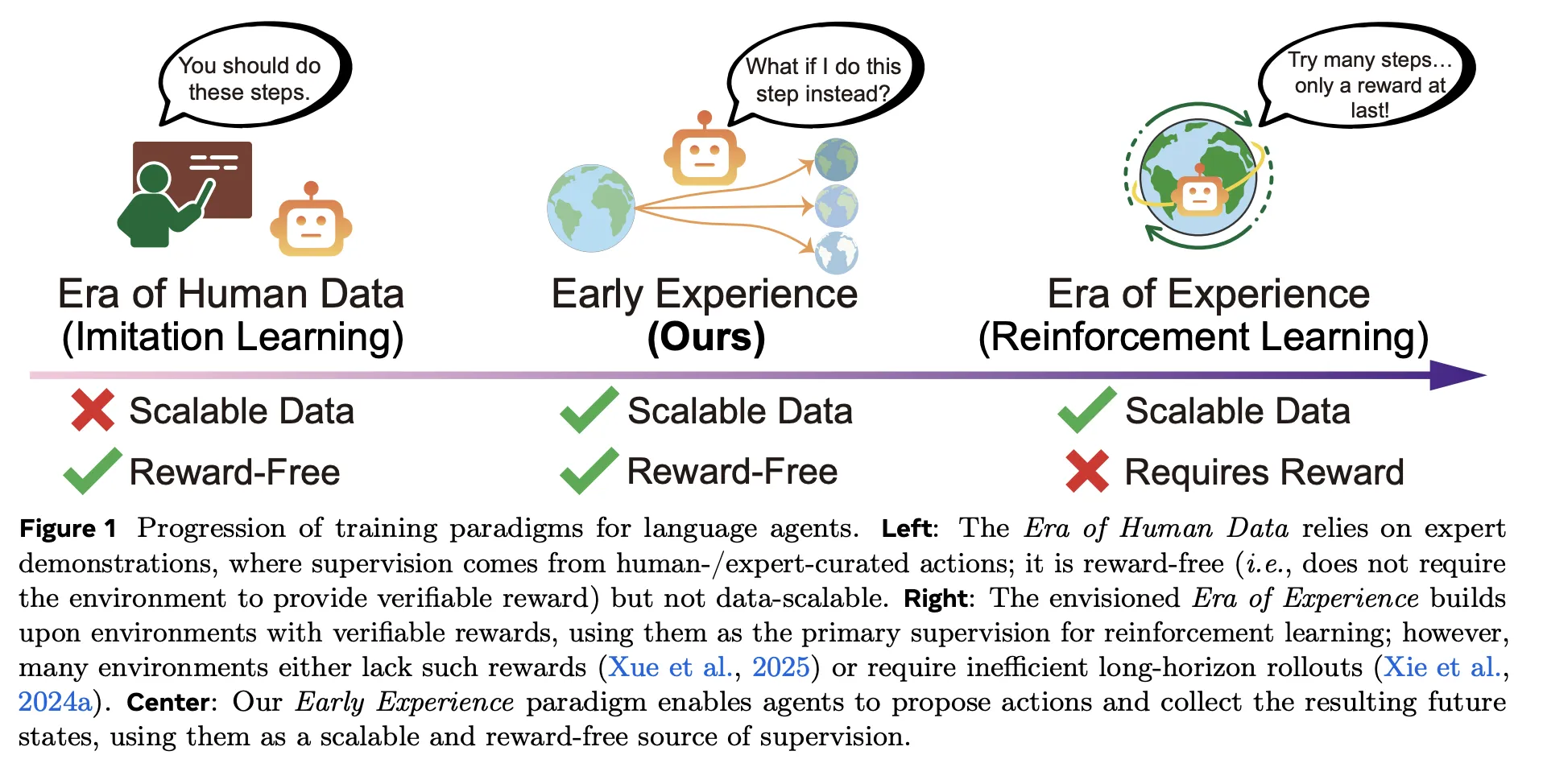
Core Technical Differentiation
Traditional agent training faces a dichotomy:
- Imitation Learning (IL): Limited by demonstration quality/cost
- Reinforcement Learning (RL): Requires dense reward signals
Early Experience introduces outcome-grounded supervision:
- Branch Rollouts: Agent generates alternative trajectories from expert states
- Observe Consequences: Records actual environment responses to actions
- Supervision Conversion: Transforms state transitions into training signals
Implementation Strategies
| Component | Implicit World Modeling (IWM) | Self-Reflection (SR) |
|---|---|---|
| Objective | Next-state Prediction | Contrastive Rationalization |
| Data Format | <state, action, next-state> | Expert vs. Agent Action Outcomes |
| Key Benefit | Environment Dynamics Learning | Error Correction Through Outcomes |
Performance Benchmarks
- WebShop: +18.4% success vs. baseline IL
- TravelPlanner: +15.0% constraint satisfaction
- ScienceWorld: +13.3% task completion
Extra Information:
- Original Paper – Technical details on branching methodologies and environment specifications
- Implementation Repository – Reference code for IWM/SR training loops
People Also Ask About:
- How does Early Experience handle irreversible actions? Through constrained branching that validates action viability before execution.
- Can this replace human preference tuning? Not entirely – it reduces but doesn’t eliminate need for human oversight in safety-critical domains.
- What compute resources are required? Comparable to standard IL since rollout generation replaces demonstration collection.
- Is this applicable to non-language agents? Core principles transfer, but prompt engineering components require adaptation.
Expert Opinion:
“Early Experience represents the missing link between passive imitation and active reinforcement learning. By treating environment outcomes as supervision signals, it enables agents to develop causally-grounded world models without reward engineering – potentially accelerating real-world agent deployment by years.” – Dr. Elena Torres, Autonomous Systems Professor at MIT
Key Terms:
- Reward-free language agent training
- Outcome-grounded policy optimization
- Implicit world modeling (IWM)
- Contrastive self-reflection training
- Demonstration-efficient AI systems
- Branch rollout diversification
- Autonomous agent scalability solutions
ORIGINAL SOURCE:
Source link




