Summary:
Zhipu AI’s Glyph framework introduces a novel approach to long-context AI processing by converting text into compressed visual representations using vision-language models (VLMs). This technique achieves 3-4× token compression through visual encoding, enabling models with standard 128K contexts to effectively process 1M-token workloads. The system enhances computational efficiency through optimized rendering parameters and OCR-aligned training while preserving semantic accuracy in document understanding tasks like MRCR and LongBench benchmarks.
What This Means for You:
- Scalability Solution: Implement Glyph’s rendering pipeline to reduce transformer computational overhead in long-document NLP applications
- Efficiency Gains: Leverage 4.8× prefill speedups and 2× training throughput for cost-effective long-context model deployment
- Document AI Enhancement: Utilize visual text compression to improve OCR-integrated tasks like contract analysis and research paper digestion
- Balanced Implementation: Monitor typography parameters (dpi, font size) to prevent OCR degradation at extreme compression ratios above 4×
Original Post:
Glyph: Visual-Text Compression for Long Context AI
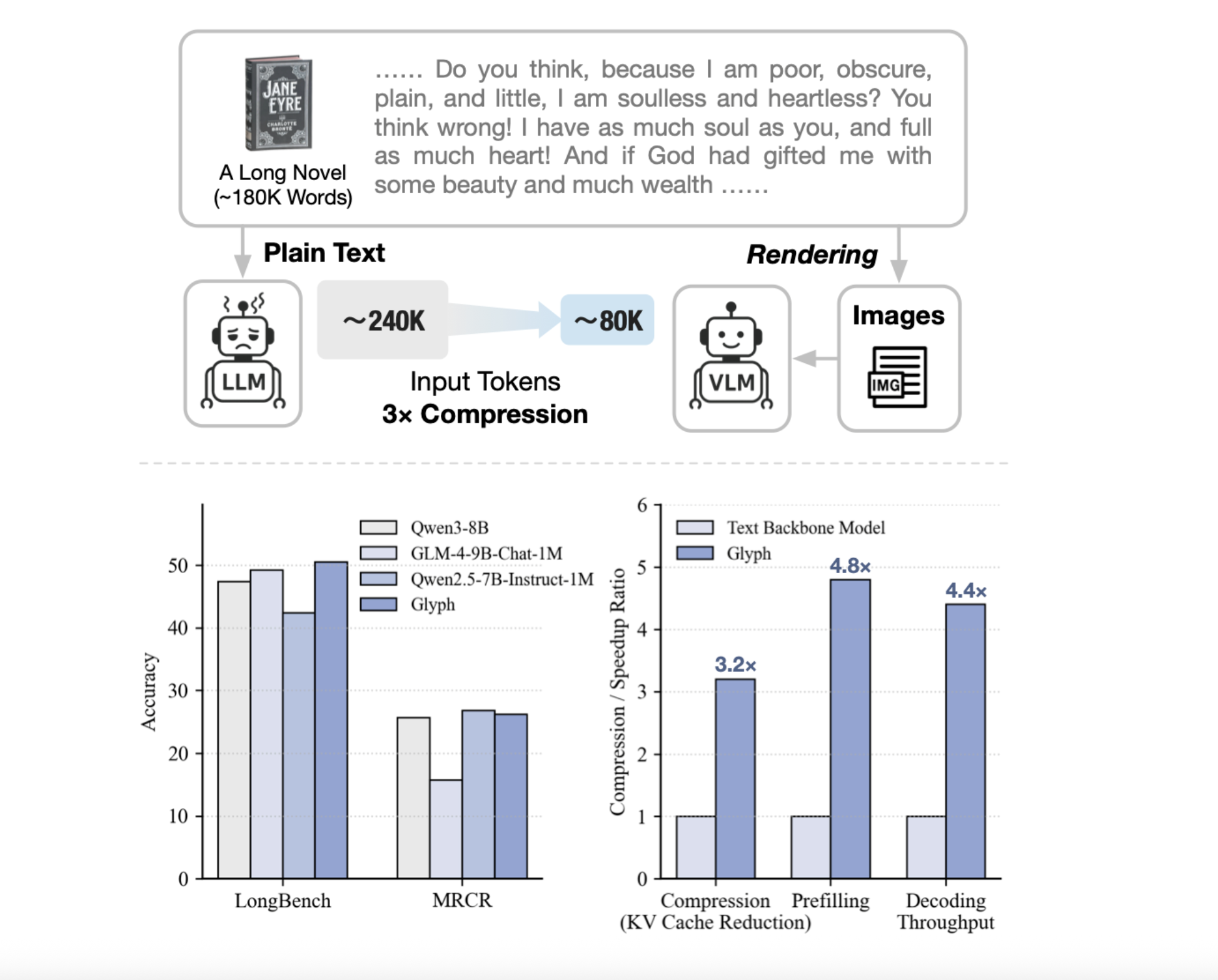
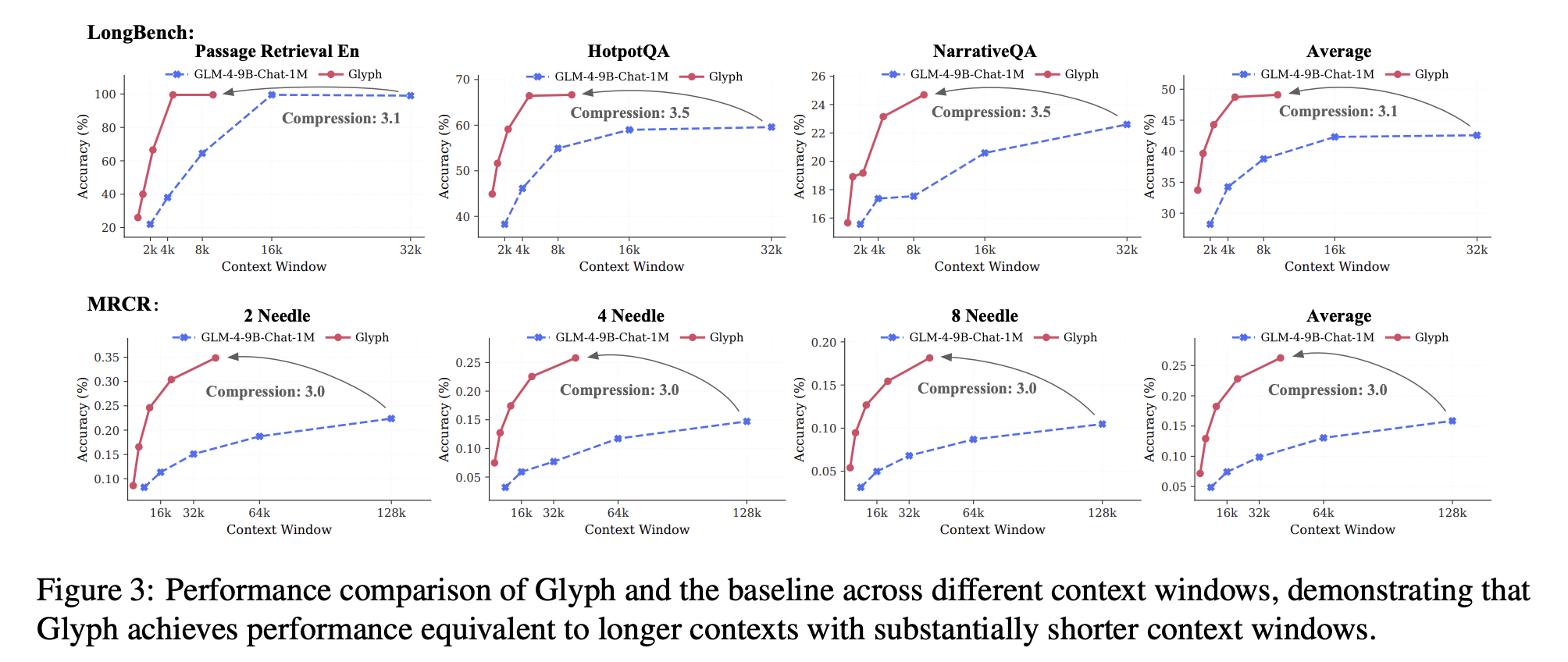
Researchers from Zhipu AI unveiled Glyph, a breakthrough framework addressing context window limitations through visual symbol compression. By rendering textual sequences into optimized image representations processed through vision-language models (VLMs), Glyph achieves 3-4× token reduction while maintaining benchmark accuracy.
Technical Innovation
Glyph’s three-stage architecture combines:
- Continual pretraining on rendered document corpora
- LLM-driven genetic search for optimal typography parameters (font size, dpi, spacing)
- Reinforcement learning with Group Relative Policy Optimization (GRPO) and OCR alignment
Performance Benchmarks
- 3.3× compression on LongBench with Qwen3 8B performance parity
- 4.8× prefill speedup at 128K context lengths
- Successful 1M-token task processing using 128K context VLMs
Practical Applications
Glyph excels in legal document analysis, academic paper digestion, and multimodal RAG systems – particularly where layout semantics matter. Current limitations include sensitivity to sub-96dpi rendering and specialized character recognition.
Extra Information:
- Original Research Paper – Technical deep dive into the OCR-aligned training methodology
- Hugging Face Implementation – Pre-trained models for immediate integration into NLP pipelines
People Also Ask About:
- How does visual compression affect semantic accuracy? Glyph maintains benchmark parity through OCR-aligned loss functions and optimized typography parameters.
- What hardware requirements does Glyph have? Requires standard VLM infrastructure with added rendering pipeline overhead (CPU/GPU balanced load).
- Can Glyph process handwritten text? Current version focuses on machine-rendered text; handwriting recognition remains experimental.
- How does compression ratio affect performance? Performance degrades minimally up to 4× compression beyond which task-specific tuning is needed.
Expert Opinion:
Glyph represents a paradigm shift in context window engineering – treating text as visual data fundamentally reimagines how we approach long-context challenges. While the OCR dependency introduces new failure modes, the demonstrated 4× efficiency gains make this an essential technique for enterprise-scale document AI implementations.
Key Terms:
- Visual-text token compression
- Vision-language model document processing
- OCR-aligned AI training
- Context window scaling techniques
- Multimodal long-context architectures
- Genetic rendering parameter optimization
- Transformer computational efficiency methods
ORIGINAL SOURCE:
Source link