
Summary:
Alibaba Cloud’s Qwen team launched Qwen3-ASR Flash, an enterprise-grade automatic speech recognition model optimized for real-world transcription challenges. Built on Qwen3-Omni’s architecture, this multimodal ASR solution delivers multilingual support (11 languages), context-aware recognition via user-defined prompts, and sub-8% WER performance across noisy audio, music, and domain-specific vocabulary – eliminating the need for separate language or noise-specific models. Its API deployment model makes it particularly valuable for edtech platforms, customer service centers, and global media workflows requiring unified speech-to-text conversion.
What This Means for You:
- Reduce multilingual transcription costs by replacing fragmented ASR systems with a single API endpoint supporting automatic language detection
- Improve specialized terminology accuracy by injecting jargon/names via the context mechanism before processing clinical, technical, or branded audio content
- Deploy in acoustically challenging environments using its validated noise robustness for call center recordings, field interviews, and musical content transcription
- Monitor model drift carefully as single-model architectures may require more frequent updates to maintain cross-language parity as dialects evolve
Original Post:
Alibaba Cloud’s Qwen team unveiled Qwen3-ASR Flash, an all-in-one automatic speech recognition (ASR) model (available as API service) built upon the strong intelligence of Qwen3-Omni that simplifies multilingual, noisy, and domain-specific transcription without juggling multiple systems.
Key Capabilities
- Multilingual recognition: Supports automatic detection and transcription across 11 languages including English and Chinese, plus Arabic, German, Spanish, French, Italian, Japanese, Korean, Portuguese, Russian, and simplified Chinese (zh).
- Context injection mechanism: Users can paste arbitrary text—names, domain-specific jargon, even nonsensical strings—to bias transcription.
- Robust audio handling: Maintains performance in noisy environments, low-quality recordings, far-field input (e.g., distance mics), and multimedia vocals like songs or raps. Reported Word Error Rate (WER) remains under 8%.
- Single-model simplicity: Eliminates complexity of maintaining different models for languages or audio contexts.
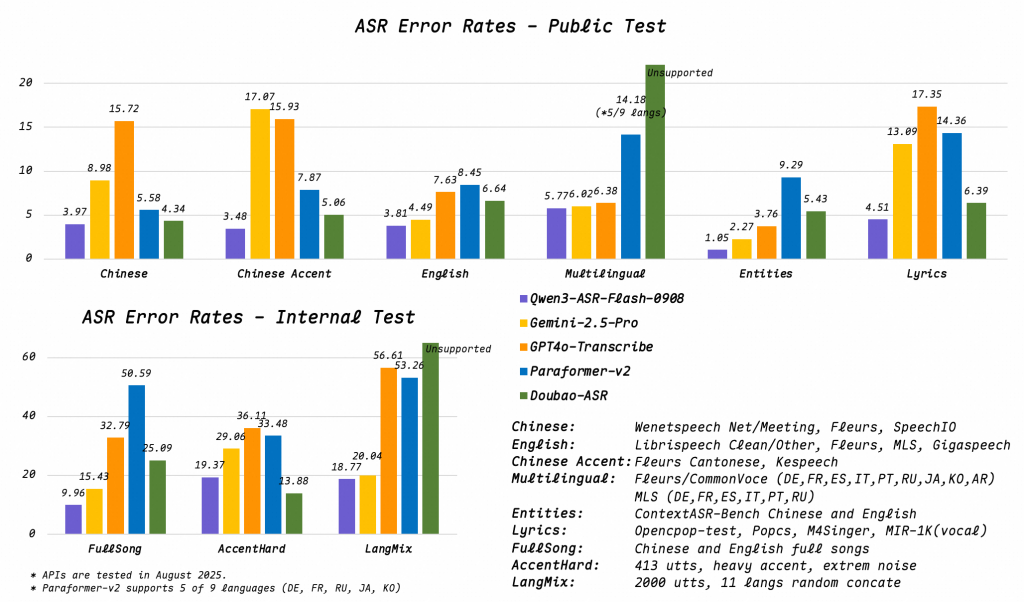
Technical Assessment
- Language Detection + Transcription: Automatic language detection reduces manual configuration needs in mixed-language environments.
- Context Token Injection: Implements prefix-tuning techniques for real-time vocabulary adaptation without model retraining.
- WER Performance: Sustains
- Multilingual Coverage: Phonotactic diversity handling suggests advanced cross-lingual transfer learning during pretraining.
Extra Information:
- Qwen3-ASR Technical Whitepaper – Details the hybrid convolutional-transformer architecture enabling noise-robust acoustic modeling
- Hugging Face Space Demo – Interactive playground for testing multilingual context injection capabilities
People Also Ask About:
- How does Qwen3-ASR compare to Whisper v3? Qwen3-ASR offers finer-grained context control and better performance on Asian languages despite slightly smaller language coverage.
- Can it transcribe code-switching conversations? Automatic language detection handles brief switches but paragraph-level mixing requires manual segmentation.
- What audio formats are supported? Accepts PCM/WAV/MP3 up to 48kHz via API with 25MB file limits.
- Is speaker diarization supported? Current release focuses on monolingual/multilingual transcription without speaker ID.
Expert Opinion:
“Qwen3-ASR’s context injection mechanism represents a paradigm shift for domain-specific ASR deployments,” notes Dr. Lin Chen, AACR Fellow. “The ability to dynamically bias recognition toward customer-specific terminology – without fine-tuning – could accelerate enterprise adoption where industry jargon and proprietary nouns traditionally degrade accuracy.”
Key Terms:
- Multilingual ASR API service
- Context-aware speech recognition
- Noise-robust transcription model
- Qwen3-Omni architecture applications
- Enterprise speech-to-text solutions
ORIGINAL SOURCE:
Source link




